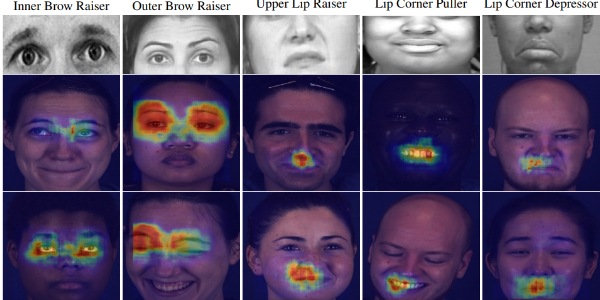
Abstract
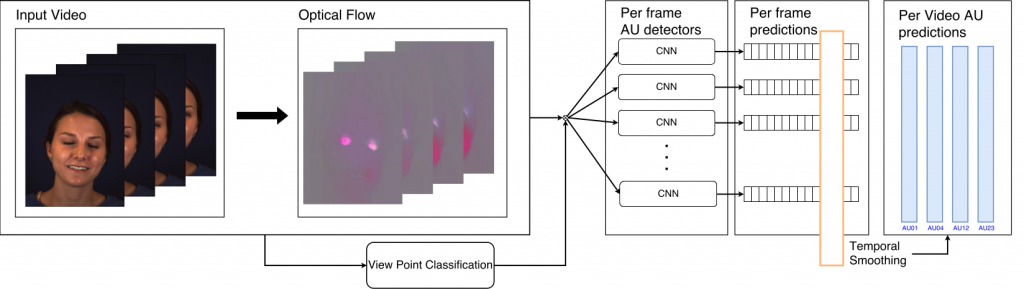
Different arrangement for the optical flow
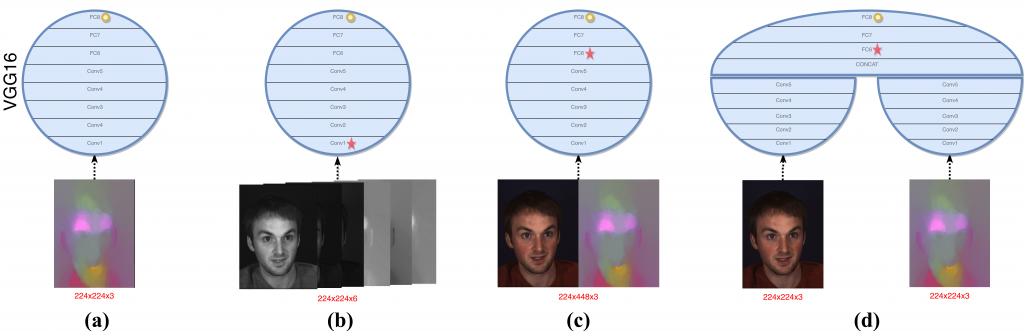
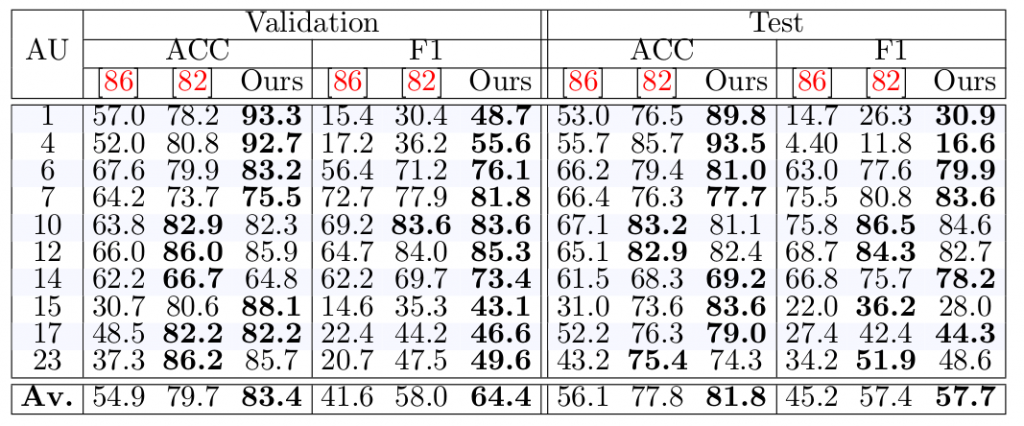
Results
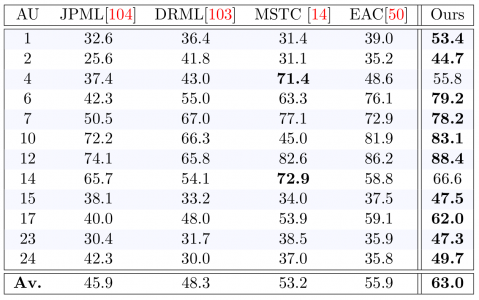

| AU | 1 | 2 | 4 | 6 | 7 | 10 | 12 | 14 | 15 | 17 | 23 | 24 | Av. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | 53.4 | 44.7 | 55.8 | 79.2 | 78.1 | 83.1 | 88.4 | 66.6 | 47.5 | 62.0 | 47.3 | 49.7 | 63.0 |
| AU | 1 | 2 | 4 | 6 | 7 | 10 | 12 | 14 | 15 | 17 | 23 | 24 | Av. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | 53.4 | 44.7 | 55.8 | 79.2 | 78.1 | 83.1 | 88.4 | 66.6 | 47.5 | 62.0 | 47.3 | 49.7 | 63.0 |